【知っておきたい「AI技術」最新事情①】 2020年代の「AI技術」の基礎知識 ~今、AIでどこまでできるようになっているのか?~
「AIを○○社が導入し、実際に業務で活用し始めた」「AI技術を使った最新のソリューションを△△社が発売した」といったニュースを日々目にするようになりました。広く使われるようになったAIという言葉ですが、具体的にはどういう技術を指すのか、仕組みはどうなっているのか、どういったことに使えるのか、最新技術でどこまでのことができるのか。 本連載ではそういった疑問に答えるべく、AI技術の基礎的な知識や最新動向、最新の事例などについて分かりやすく紹介していきます。 第一回の今回はAI技術の種類とその応用例、近年の動向などについて取り上げます。AI技術について研究している博報堂DYホールディングス マーケティング・テクノロジー・センターの木下陽介と田原將志の二人に話を聞きました。
―AI技術の種類と、近年の動向を教えてください。
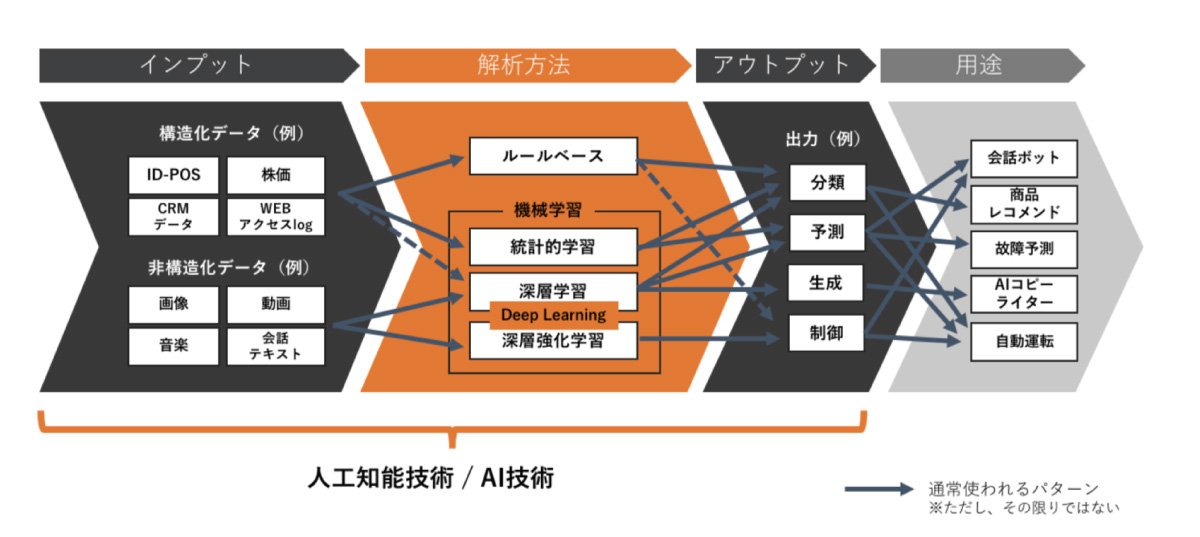
AIに関する技術要素は「インプット」「解析方法」「アウトプット」の3種類に分けて整理すると理解しやすく、これらを「チャットボット」や「商品のリコメンド」といった「用途」に合わせて使っていく、という形になります。基本的にはインプットするデータと何をアウトプットするかは実現したい用途によって事前に定まることが多く、それを解析する方法が何パターンかある中で最適なものを選定する、といった具合です。
この「インプット」「解析方法」「アウトプット」の中で、特に言及されることの多い解析方法について説明します。大まかに分けて「ルールベース」「機械学習」の2種類があり、機械学習の中でも特に「深層学習」が近年盛んに研究・応用されるようになっています。ルールベースとは、プログラミングをやったことがある方ならお分かりになるかと思いますが、「if文」のような形で人間が事前に設定した条件に応じて処理を行う技術です。「Aの時にはこういう挙動」「Bの時にはこういう挙動」「それ以外はこういう挙動」と人間が設定したルールに応じて処理するものになります。
機械学習の中には、購買情報である「ID-POS」など構造化データを使って将来の売上など未来の推移を予測するような時に使う「統計的学習」や、先ほどお話した「深層学習」があります。深層学習はディープラーニングとも言われ、少し前であれば「AIを使うと目新しいから取り敢えず何かやってみよう」とAIを使うモチベーションが先行してとりあえず技術検証を目的としたPoCを実施したものの、AIの精度が実用化レベルに至らず止まってしまう事例も多かったのですが、最近は地に足が付いた形で社会実装できるような段階まで来ています。画像やテキストではかなり実用化が進んでおり、音楽や音声、動画でも事例が出始めています。
―ルールベースと機械学習では、同じAIとは言っても考え方や用途自体が違うということでしょうか。
同じ部分と違う部分がありますね。例えば条件分岐の観点からルールベースと機械学習の違いを説明すると、ルールベースは先ほどお話した通り条件分岐のルールを人間が決めます。そのため挙動が明確で制御が簡単な一方、対象が複雑になると、どういう時にどういう分岐を作るかを考えるのが難しくなりますし、分岐の作成自体にも非常に手間がかかります。
一方で、機械学習にも条件分岐はあります。ただ、機械学習の場合は条件の分岐自体を“教師データ”と言われるデータからAI(機械)が自動で学習するんです。こう言うと機械学習が万能に思えるかもしれませんが、以前からある深層学習以外の機械学習の場合は、画像分類など複雑な事象に対しては学習させることが難しいという課題がありました。
これに対して近年注目を集めている深層学習は、大量の教師データを準備する事ができれば、例えば映像に人が写っているかを判定したり、何を話しているかをテキスト化していく翻訳サービスなど、画像や音声など複雑な事象に対しても人の役に立つ実用化レベルまでできるようになりつつあります。
博報堂DYホールディングスマーケティング・テクノロジー・センター 木下陽介
最適な手法を選ぶことが一番重要
―では世の中のAIは深層学習を使ったものばかりになっているのですか。
そんなことはありません。それぞれの解析手法にメリットとデメリットがあります。例えば、webサイトで出てくるようなFAQのチャットボットの多くはルールベースで作られています。条件分岐を予め設定するだけなので、エンジニアでない人でも簡単に作れますし、コストもあまりかかりません。
ただ、FAQの質問に対して、口語的な表現だったり、判断しにくいような回答をする利用者も多くいます。例えば、「お腹が減りました」と書いて欲しいところに、「腹減った」という書き込みがある、といった具合です。こういった表現を、どういう文意か判断する際に深層学習以外の機械学習や深層学習を使うケースがあります。専門用語などが多く使われるFAQの場合は、専用のデータベースを使って判断することもありますね。ルールベースと機械学習はできることや使い方がそれぞれ異なるので、やりたいことに合わせて上手く組み合わせて使うことが大切になります。
深層学習の優れている点は先ほどご説明したので、いくつか課題を挙げますと、専門的な知識がないと扱いづらい、大量の教師データを用意する必要がある、計算の負荷が高くAIを学習させるコストが高い、といったことがあります。ただ最近になって、簡易的な機械学習や深層学習であれば、プログラミングせずに利用できるノーコード開発ツールが出始めているので、多くの人が扱えるようにはなってきています。計算の負荷についても、画像を高速で処理を行うことのに適したGPU(Graphics Processing Unit)が登場するなど安価で計算処理を行う環境が整ったことで精度向上を見込めるケースも増え、今後もチップセットの性能向上に伴いコンピューターの処理能力は年々上がっていくので、時間が解決してくれる部分もあります。
AIを使う上で大切なのは、「この解析方法が一番優れている」といった形で使用することではなくて、課題やデータ量、使う人の技術力、かけられるコストなどに応じて、最適な手法の組み合わせを選ぶことにあります。機械学習や深層学習をノンプログラミングでできるツールが増えてきたこともあり、ユーザーの選択の幅は以前より広がっていますし、AIを使うハードルは下がってきています。課題や状況に合った形でAIを導入する、ということは多くの企業にとって現実的なものになってきています。

博報堂DYホールディングスマーケティング・テクノロジー・センター 田原將志
―ルールベース、深層学習以外の機械学習、深層学習のそれぞれで同様の処理を行う場合の挙動の違いを知りたいのですが、具体例を挙げて教えていただけますか。
果物の画像を分類するケースで説明しましょう。ルールベースの場合、「色」「形」などの特徴と「赤くて丸い→りんご」「黄色くて丸い→みかん」といったルールを人間が事前に設定します。そしてそのルールに基づき「赤くて丸い画像→りんご」「黄色くて丸い画像→みかん」といった具合に判定していきます。この場合問題になるのが、ルールを事前に設定する際には想定していなかった皮の色が黄色いりんごの画像を判定するようなケースで、ルールベースではそれを正しく判定することはできません。
深層学習以外の機械学習であれば、先ほどの色や形などのシンプルな特徴に加え、「ヘタの長さ」「窪みの深さ」といったより詳細な特徴を判定ロジックに追加し、また「ヘタが〇〇mm以上△△mm以下ならりんご」「窪みが〇〇mm以上□□mm以下ならみかん」といったルールを、教師データから機械が自動で学習し判定します。ただこれでも、教師データに含まれていなかった、例えば包丁でカットして皿に盛られたりんごの画像を判定しようとすると当然正しく判定することはできず、様々なケースに対応できる人間の水準に達することは難しいです。
一方深層学習の場合、木に実っているものやカットされているもの、手書きのものなど様々なタイプのりんごやみかんの画像も含めてあらかじめ大量に収集しAIに学習させます。深層学習では深層学習以外の機械学習とは異なり、「色」「形」「ヘタの長さ」など判定ポイントとなる特徴自体をAIが自動的に発見していくのです。これによってAIはりんごらしさやみかんらしさといった特徴を学習し、多種多様なりんごやみかんの画像を判別することができるようになります。深層学習においては解析手法に加えて、どれだけバリエーション豊富でかつ大量のデータを教師データとして学ばせるかということも、AIの精度を分ける大切なポイントとなってきます。
深層学習を活用した社会実装事例が進む
~今後の課題はデータ収集と社会実装できる人材の育成~
―深層学習において実用レベルにあるという画像とテキストではどんな事例がありますか。
画像については、工場の不良検知や小売店での顧客の動きの解析、監視カメラの異常検知、スポーツのパフォーマンス分析などに使われています。また深層学習を使った顔認識が精度が大幅に上がったことで社会実装が進んでいて、例えばイベントの入場券の代わりに顔をIDとして使う、といった事例が増えています。
画像から人の動きを解析することもどんどんできるようになってきています。どんな姿勢で画像に映っているか、左手と右手の位置はどこか、といったことが分かったり、フォームの特徴を分析する事例*などが出てきています。
*SportsTechnologyLabの事例
https://preferred.jp/ja/projects/sports-analytics/
―テキストはいかがでしょうか。
従来からある用途として一番多いのはスパムメールを判定して選り分けることですね。近年はそれが更に進化していて、ただスパムか否かを判別するだけではなく、どういった内容のメールなのか自動でタグ付けすることができるようになってきています。
分類、という用途は他の分野でも広がっていて、ニュースサイトの記事の内容を自動で解析してタグ付けするようなことが可能です。従来であれば、例えば自動車会社の営業の方が、複数の新聞記事をチェックしたり、ニュースサイトで車のニュースの一覧に目を通す、といったケースが多くあったと思います。これに対して、新聞やニュースサイトの記事を自動的に深層学習で分類してタグ付けするようにすれば、「車の乗り心地に関する記事があったときだけ新着ニュースの通知を受ける」といったことができるようになります。
―深層学習について、「ここ数年で更に進化した」といったことはありますか。
AIは、「その結論がどうやって出たのかがブラックボックスになってしまい、人が説明できないことがビジネス活用上で課題だ」とよく指摘されて来ました。ですが、近年は深層学習においてその課題を解決するような、どうやってその結論が出たかAIの判断根拠を可視化するような技術の研究が活発に行われています。例えば花の画像を分類する場合に、「この画像はチューリップだ」という判断を、「花びらの先っぽの部分」をAIは注視して決めたということが分かるようになっているんです。一度そのようなAIの挙動が把握できれば、次回以降判定させる画像として「花びらの先が上手く写っていない画像は対象外にする」といったAIを運用する上でのルールを検討することができたり、逆に「花びらの先が上手く写っていない画像を重点的に教師データに追加」し、よりAIの精度を高めていくことなどができるようになるんです。
―まだ残っている課題にはどのようなものがあるのでしょうか。
先ほども少しお話しましたが、大量の教師データをどうやって集めるか、という部分ですね。犬や猫、車といったものであれば、既に世の中に多数のデータが存在しているので教師データには困りません。ですが例えば、我々広告会社であれば、ある広告画像に個別商品や特定のタレントが実際に写っているかどうかを認識したい、といった用途が考えられます。その場合、世の中に存在するそれらの写真を大量に集めるのは非常に手間やコストが掛かりますし、そもそもそんなに多くの画像自体が存在しない、といったこともあり得ます。そういった課題を解決するために、少量の教師データでAIを学習させる手法や、CG画像を教師データに加える手法など様々なアプローチの研究成果が発表されており、我々もこういった研究は日々チェックするようにしています。
もう一つ上げられるのがAI技術を社会実装していく人材の育成です。AI技術の社会実装を進めていくためには、そのAI技術が精度が高く「正しいAI技術」になっているかだけでなく世の中の役に立つ「使えるAI技術」になっているかの両方を理解しプロダクトやサービスを実装できる人材が増えていくことが大事だと思っています。計算の対象が自動運転のようなものになると、間違いが起こること自体が許されません。こういった間違いが起こらないAIを作るべく、精度を高める正しいAIを作ることは大事であり、正しい技術をつくっていくのは引き続きデータサイエンティストの役割になると思います。一方で、我々のようにマーケティング目的でAIを使う場合、そのAI技術自体は目新しくないものであったり精度が多少落ちたとしても、今までできなかったことがリーズナブルなコストで解決される事ができれば新しいビジネスの収益源となります。「使えるAI技術」を見極めサービス、ビジネス化していく旗振り役になるのはテクノロジストだと思っています。今後は、どういった対象にAIを使うか、そこには精度がどれくらい求められるのか、テクノロジストとデータサイエンティストが役割をクロスオーバーしながら協業し世の中にとって役に立つAI社会実装のケースになるか皆さんの目に触れて使ってもらえる事例をどんどん増やしていきたいと思っております。僕らも日々勉強しながらプロジェクトをたくさん動かし世の中に評価される社会実装事例を作っていき、失敗も含めて今後どういった進め方がベストケースになるのかみなさんに還元したいと思っております。
この記事はいかがでしたか?
-
 博報堂 研究開発局 主席研究員
博報堂 研究開発局 主席研究員
博報堂DYホールディングス マーケティング・テクノロジー・センター 開発1グループ グループマネージャー
チーフテクノロジスト2002年博報堂入社。以来、マーケティング職・コンサルタント職として、自動車、金融、医薬、スポーツ、ゲームなど業種のコミュニケーション戦略、ブランド戦略、保険、通信でのダイレクトビジネス戦略の立案や新規事業開発に携わる。
2010年より現職で、現在データ・デジタルマーケティングに関わるサービスソリューション開発に携わり、生活者DMPをベースにしたマーケティングソリューション開発、得意先導入PDCA業務を担当。
2016年よりAI領域、XR領域の技術を活用したサービスプロダクト開発、ユースケースプロトタイププロジェクトを複数推進、テクノロジーベンチャープレイヤーとのアライアンス、共同研究も行っている。
また、コンテンツ起点のビジネス設計支援チーム「コンテンツビジネスラボ」のリーダーとして、特にスポーツ、音楽を中心としたコンテンツビジネスの専門家として活動中。
-
 株式会社博報堂 研究開発局 研究員
株式会社博報堂 研究開発局 研究員
博報堂DYホールディングス マーケティング・テクノロジー・センター 開発1グループ テクノロジスト2016年博報堂入社。統計解析、機械学習を活用したマーケティング・ソリューションの研究開発に従事。現在はAI技術を活用したプロダクト開発を中心に、XR領域のユースケースプロトタイピングやスマートシティ領域のサービス開発などを行っている。